服务端
架构
技术架构
- 后台端: Vue3 + TypeScript + Pinia + Element Plus
- 前台端: NuxtJs3 + TypeScript + Pinia + Element Plus
- 接口端: FastAPI + Pydantic + Tortoise-orm
- 数据库: MySQL>=5.7
- 缓存层: Redis
- 服务部署: Nginx
主要特性
- 路由自动根据目录自动注册
- 采用常见的MVC结构(上手更容易)
- 内置基于RBAC的权限管理的功能
- 开箱即用,内置常用的工具和组件
内置功能
- 用户管理:该功能主要完成系统用户配置。
- 部门管理:配置系统组织机构(公司、部门、小组)
- 岗位管理:配置系统用户所属担任职务。
- 菜单管理:配置系统菜单操作权限访问路径等。
- 角色管理:配置角色菜单权限分配
- 邮件配置:配置电子邮件发送功能
- 操作日志:系统操作日志记录和查询
- 定时任务:管理定时任务的(新增、修改、删除)
- 系统缓存:管理系统产生的缓存(可自行清理)
- 附件管理:管理用户上传的图片和视频
- 文章管理:管理文章的(新增、修改、删除)
- 文件存储:管理文件的存储(本地存储、阿里云OSS、腾讯云OSS、七牛云OSS)
- 操作日志 记录用户的登录、操作等日志信息,便于追踪和审计。
- 接口文档 FastAPI自动生成的Swagger UI接口文档,方便前后端开发人员对接。
- ....
目录结构
├─📂 server
│ ├─📂 apps // 应用目录
│ │ ├─📂 admin // 后台应用
│ │ │ ├─📂 routers // 控制器
│ │ │ ├─📂 schemas // 响应层
│ │ │ ├─📂 service // 逻辑层
│ │ │ ├─📄 config.py // 配置
│ │ │ ├─📄 interceptor.py // 拦截器
│ │ │ ├─📄 middleware.py // 中间键
│ │ ├─📂 api // 前台应用
│ │ │ ├─📂 routers // 控制器
│ │ │ ├─📂 schemas // 响应层
│ │ │ ├─📂 service // 逻辑层
│ │ │ ├─📄 config.py // 配置
│ │ │ ├─📄 interceptor.py // 拦截器
│ │ │ ├─📄 middleware.py // 中间键
│ │ ├─...
│ │
│ ├─📂 common // 公共目录
│ │ ├─📂 enums // 枚举目录
│ │ ├─📂 models // 模型目录
│ │ ├─📂 utils // 工具目录
│ │ ├─...
│ │
│ ├─📂 kernels // 核心逻辑
│ │ ├─📄 cache.py
│ │ ├─📄 database.py
│ │ ├─📄 events.py
│ │ ├─...
│ │
│ ├─📂 plugins // 插件目录
│ │ ├─📂 mail // 邮件服务
│ │ ├─📂 msg // 消息服务
│ │ ├─📂 sms // 短信服务
│ │ ├─📂 storage // 存储服务
│ │ ├─📂 wechat // 微信服务
│ │ ├─...
│ │
│ ├─📂 public // 公开目录
│ │ ├─📂 static // 静态文件目录
│ │ ├─📂 storage // 资源存储目录
│ │ ├─...
│ │
│ ├─📂 sql // 安装SQL
│ │ ├─📄 install.sql
│ │
│ ├─📄 .env // 环境配置
│ ├─📄 .example.env // 配置模板
│ ├─📄 .gitignore // Git配置
│ ├─📄 config.py // 全局配置
│ ├─📄 events.py // 事件管理
│ ├─📄 exception.py // 异常管理
│ ├─📄 hypertext.py // Http管理
│ ├─📄 manager.py // 启动的文件
│ ├─📄 middleware.py // 全局中间件
│ ├─📄 README.md // README
│ ├─📄 requirement.txt // 依赖包
异常处理
- 异常处理位于根目录的
exception.py里面主要用于捕获各种异常,并且抛出json格式 AppException是自定义异常,平时逻辑层需要抛出异常可以使用这个类。- 示例:
# 导入异常类
from exception import AppException
# 抛出异常
if await AuthAdminModel.filter(nickname=post.nickname).first().only("id"):
raise AppException("昵称已被占用")
中间件
FastApi是单应用单模块的框架,他是不支持多模块的,但是我们项目是多模块的, 所以在我们使用中间件的时候需要自行判断一下请求来源,再决定是否要走中间件。
中间件定义位置
- 不是那个位置都可以放中间件,中间件的加载需要遵循一定的规则才可以。
- 1、可以放在对应模块的目录下 admin/middleware.py, api/middleware.py
- 2、可以方法源码的根目录下面 server/middleware.py
- 3、文件名称只能是
middleware.py不能是其它的
如何定义中间件
from fastapi import FastAPI, Request
from starlette.middleware.base import BaseHTTPMiddleware, RequestResponseEndpoint
# 此方法是用来注入自定义中间件的
def init_middlewares(app: FastAPI):
logs_middleware: typing.Type[any] = LogsMiddleware
app.add_middleware(logs_middleware)
# 这个类就是自定义的中间
class LogsMiddleware(BaseHTTPMiddleware):
def __init__(self, app: ASGIApp):
super().__init__(app)
pass
async def dispatch(self, request: Request, call_next: RequestResponseEndpoint) -> Response:
# 执行方法
response = None
try:
response = await call_next(request)
except Exception as e:
errno = e
# 发送异常
if errno:
raise errno
# 执行完成
return response
拦截器
注意: 拦截器文件只能放到对应的模块目录下,并且命名为 interceptor.py
# 注入拦截器
obstruction: Dict[str, List[str]] = {
"LoginInterceptor": [str], # 列表里面的值是忽略不要拦截的路由
"PermsInterceptor": [str]
}
# 拦截器1
class LoginInterceptor:
@staticmethod
async def handler(request: Request, bearer: HTTPAuthorizationCredentials = Depends(HTTPBearer())):
# 这里可以做你的路由拦截逻辑
return True
# 拦截器2
class PermsInterceptor:
@staticmethod
async def handler(request: Request):
# 拦截逻辑
return True
部署
支持
注意
您的Star是我坚持下去的动力,如果您觉得还不错,帮忙点个Star吧!
准备工作
【源码下载】:
环境要求
| 运行环境 | 要求版本 | 推荐版本 |
|---|---|---|
| Python | >=3.10.* | 3.12.* |
| Mysql | >=5.7 | 8.0 |
| Nginx | 无限制 | 最新LTS版 |
| Node | >=20.* | v20.14.0 |
宝塔部署
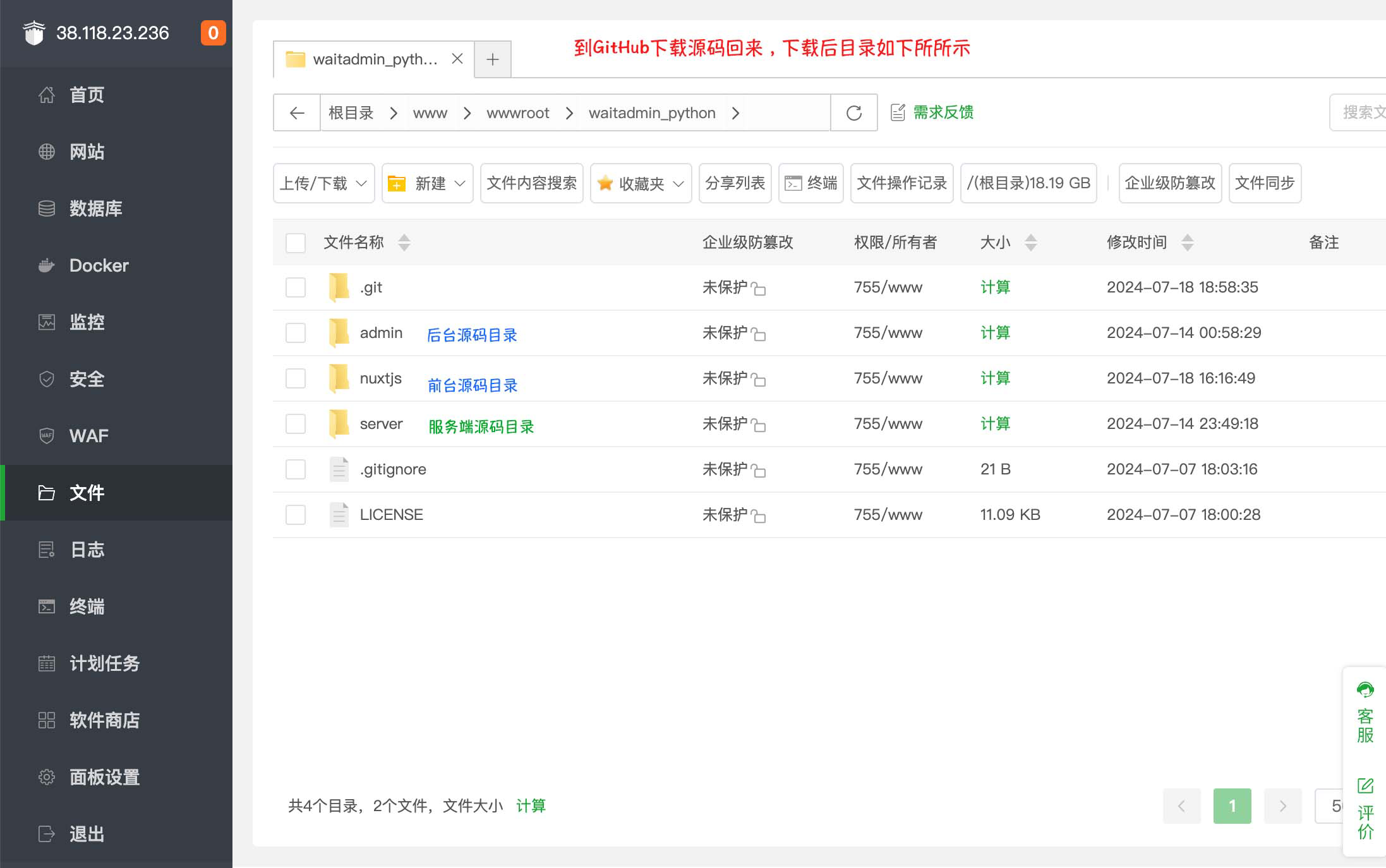
第1步: 下载源码
1.到Github/Gitee下载源码压缩包,放到服务器上并解压。
2.那您就会得到如下图所示的目录结构 (下载时别忘记Star哦)。
第2步: 创建数据库
1.我们需要创建数据库,并且把我们的数据结构导入到数据库中。
2.数据结构文件放在下载的源码 server/sql/install.sql。
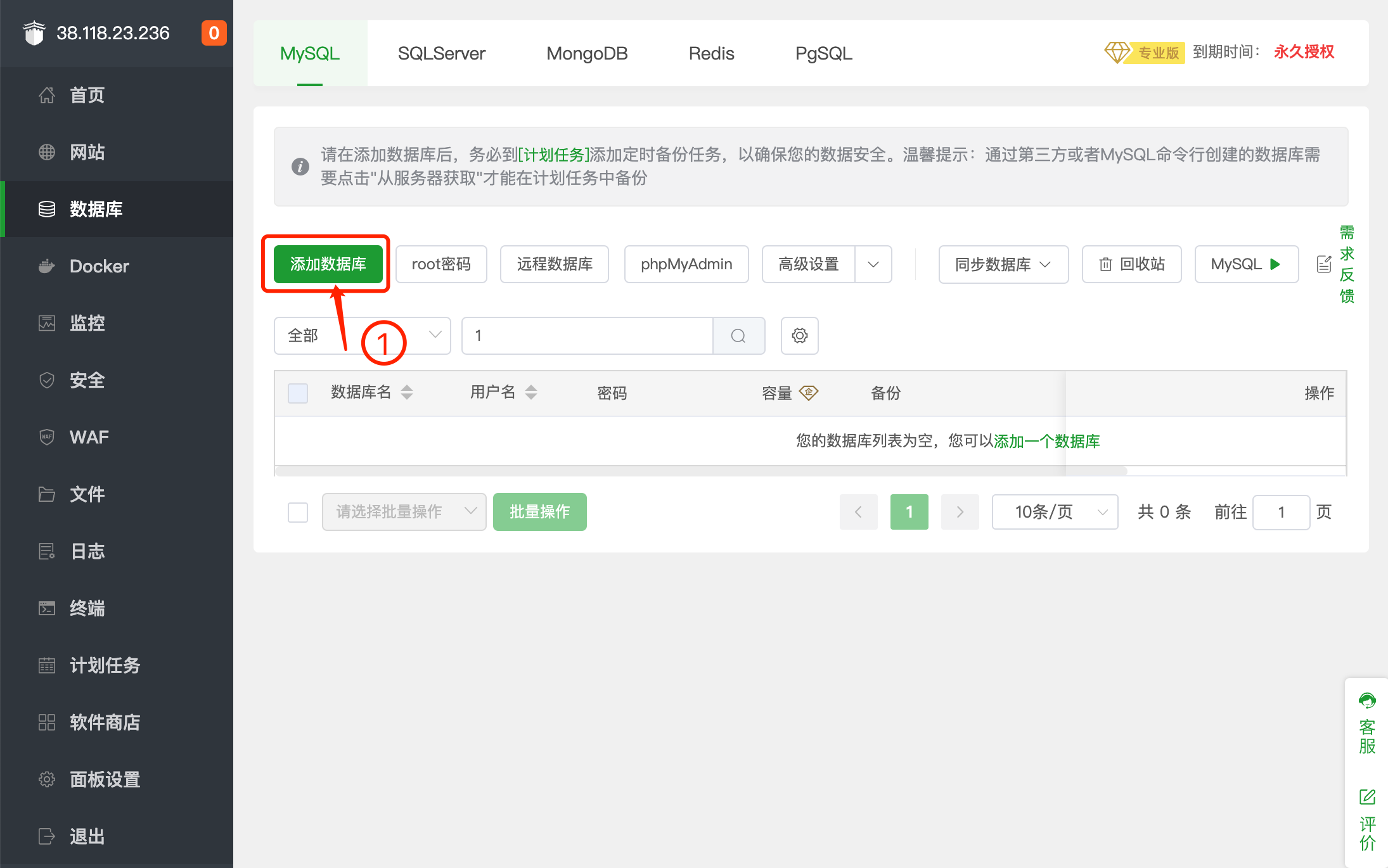
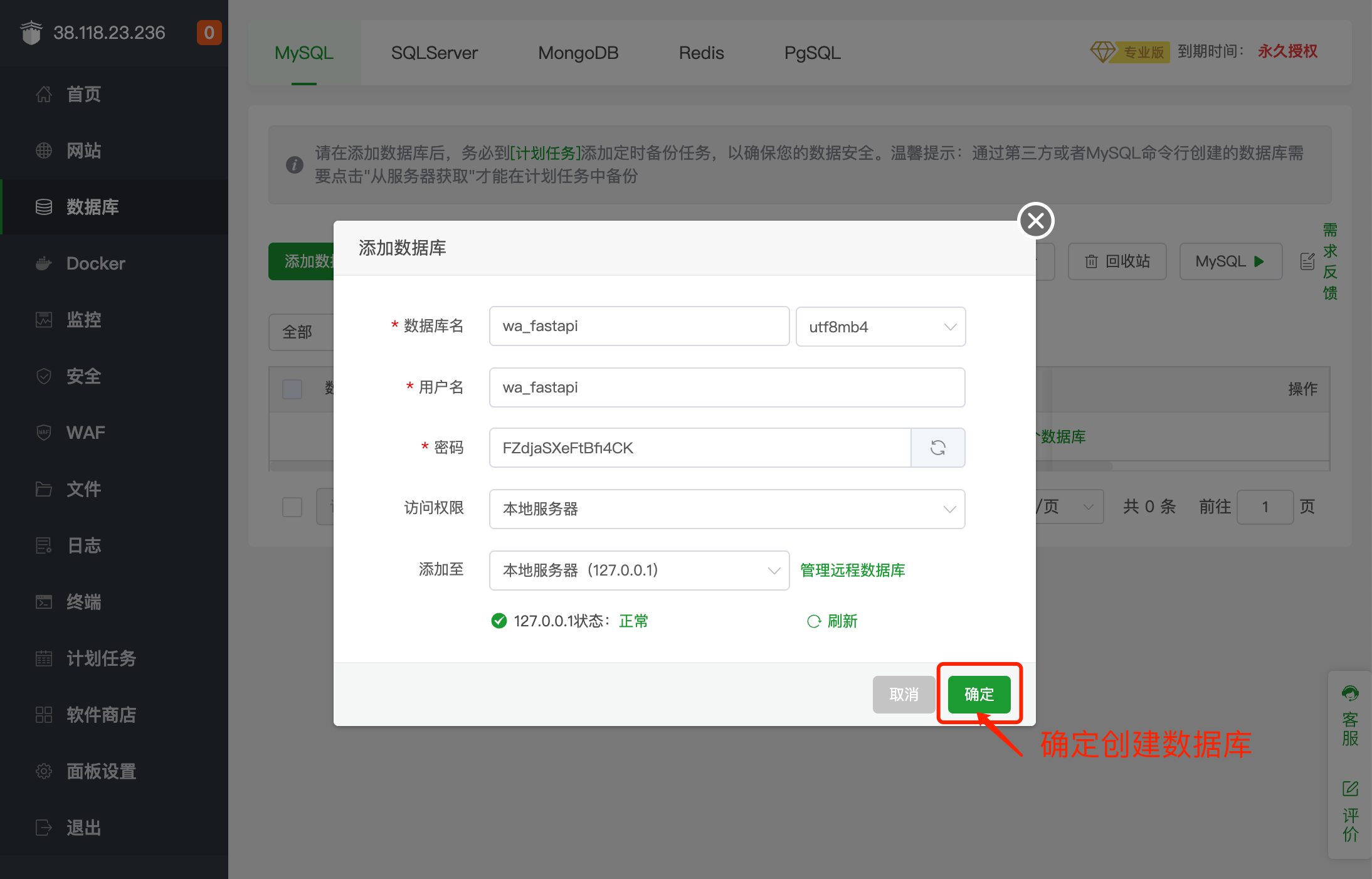
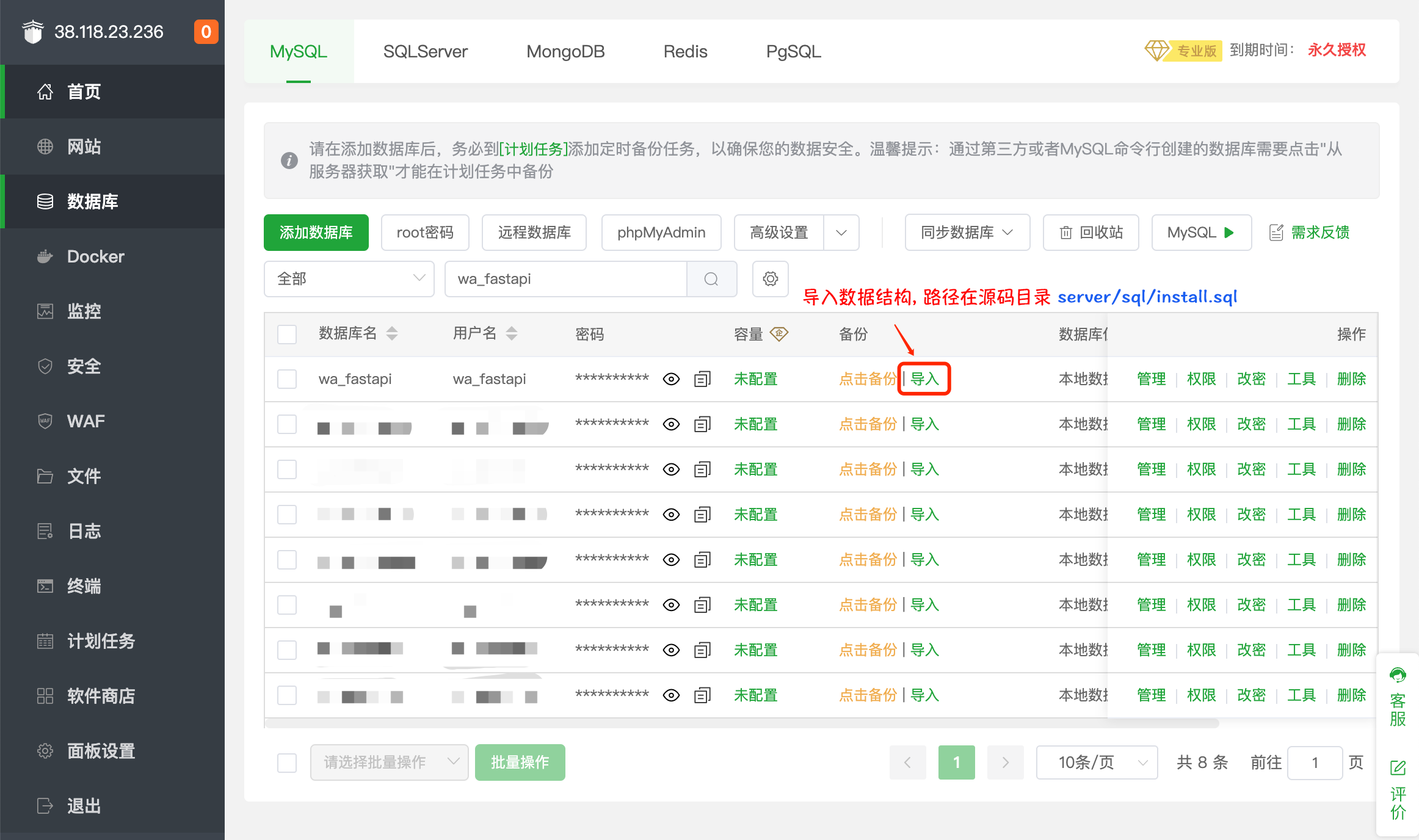

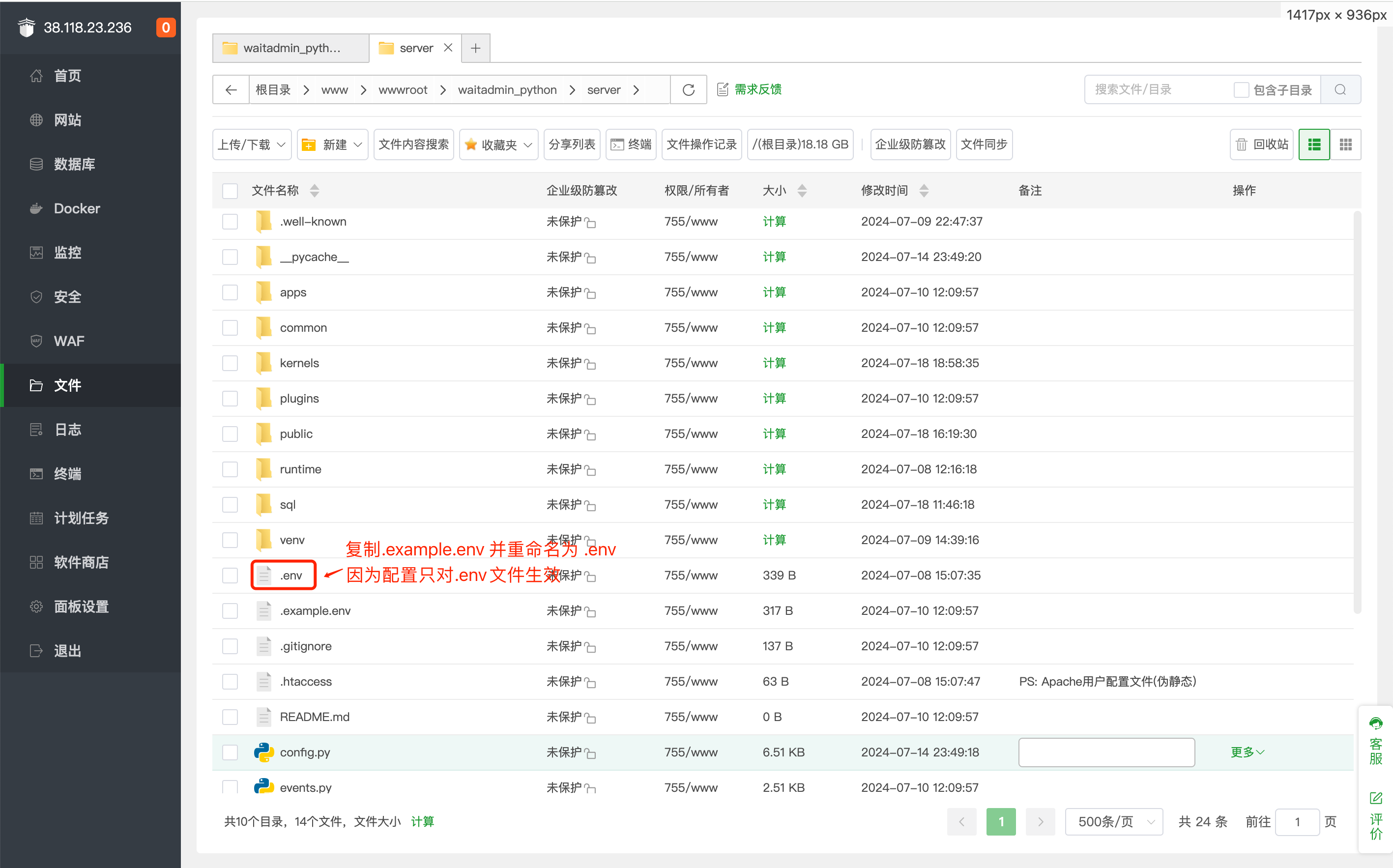
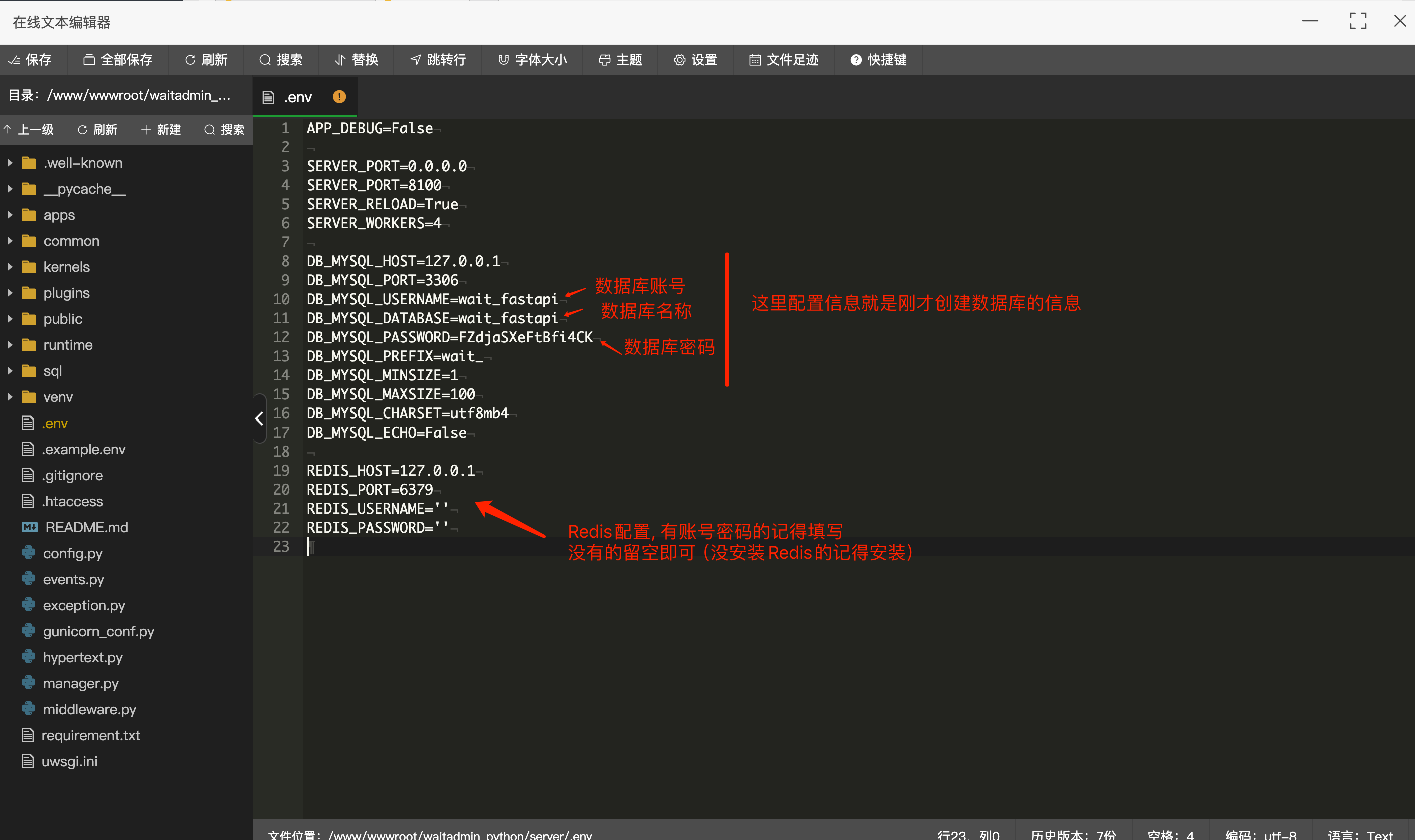
第3步: 修改配置文件
1.到server目录下,把.example.env复制一份,并重命名为 .env 2.修改.env的数据库配置和Redis配置
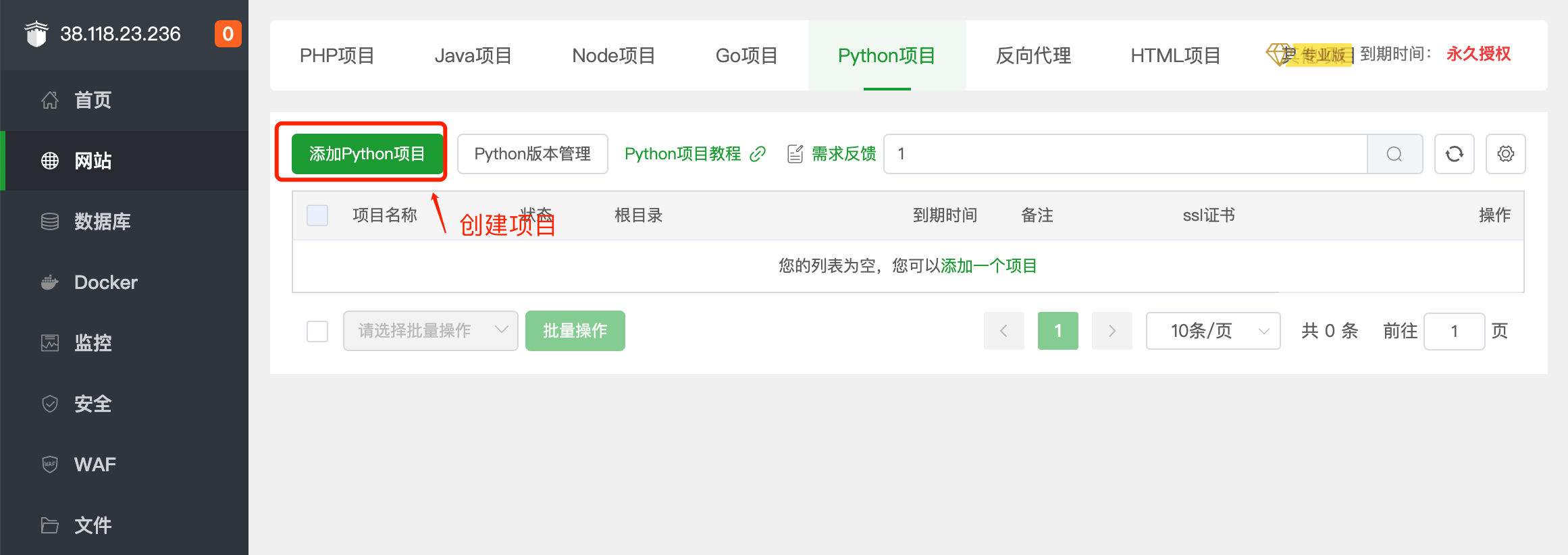
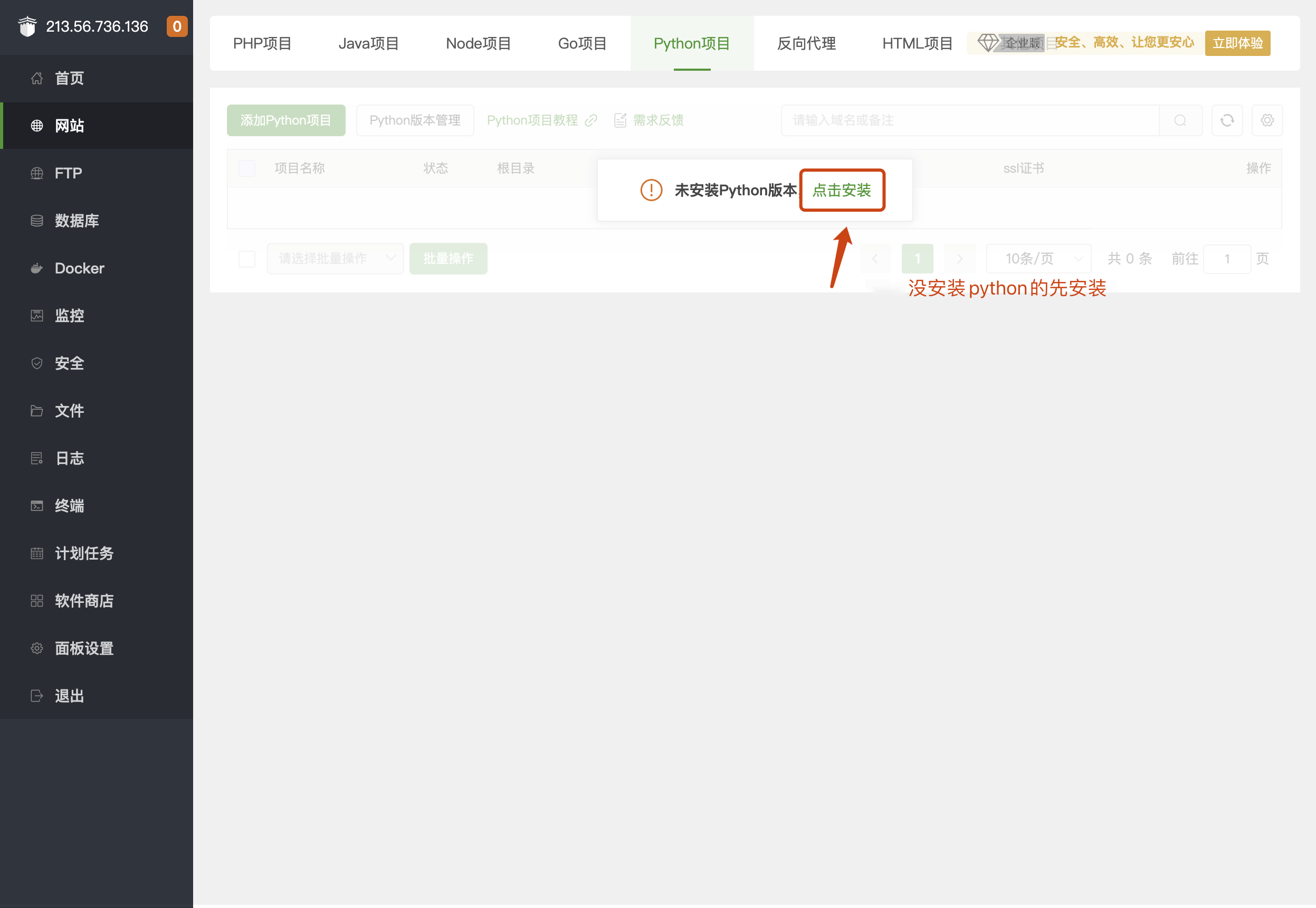
第4步: 添加Python项目
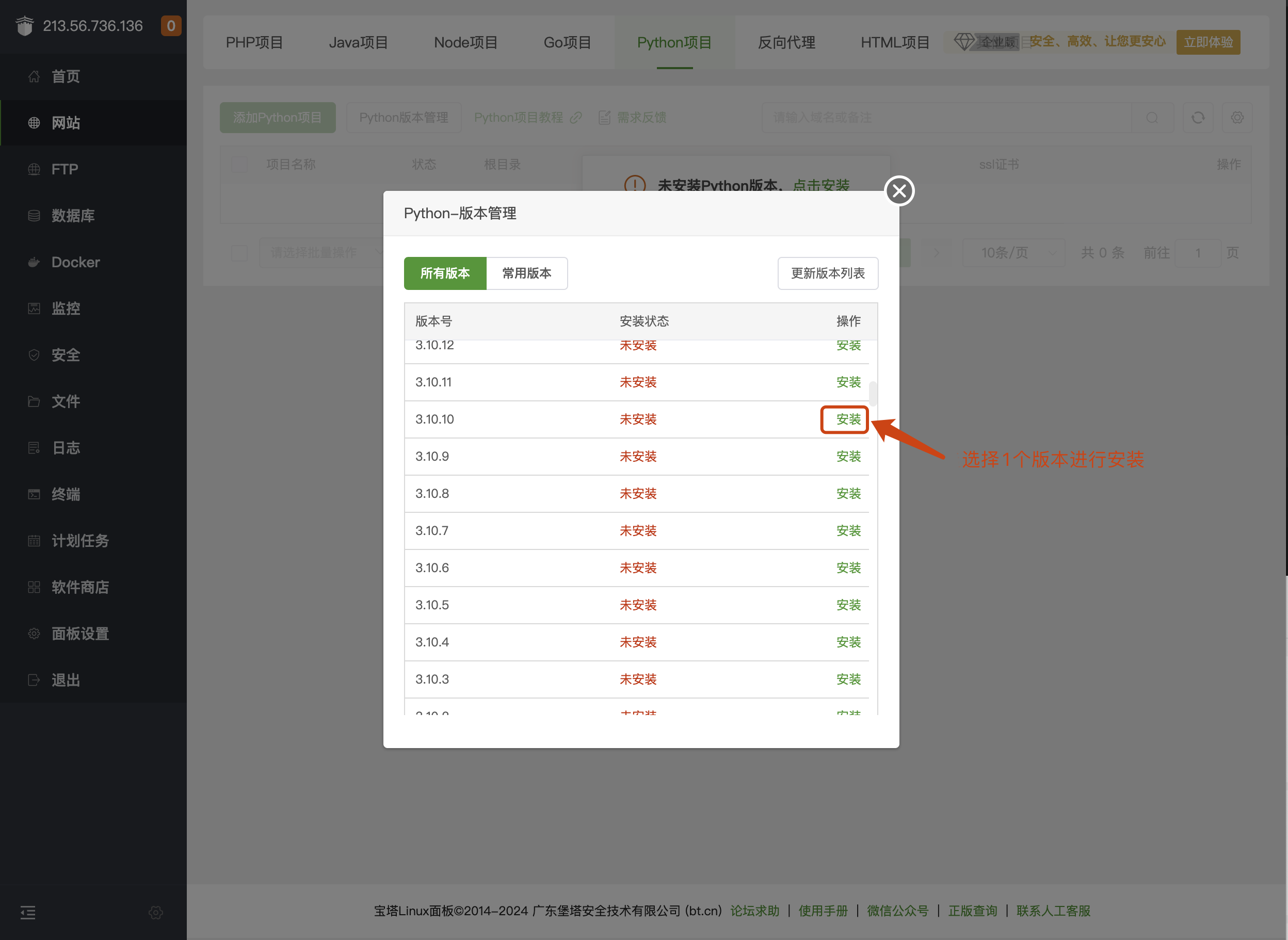
第5步: 按要求填写好信息
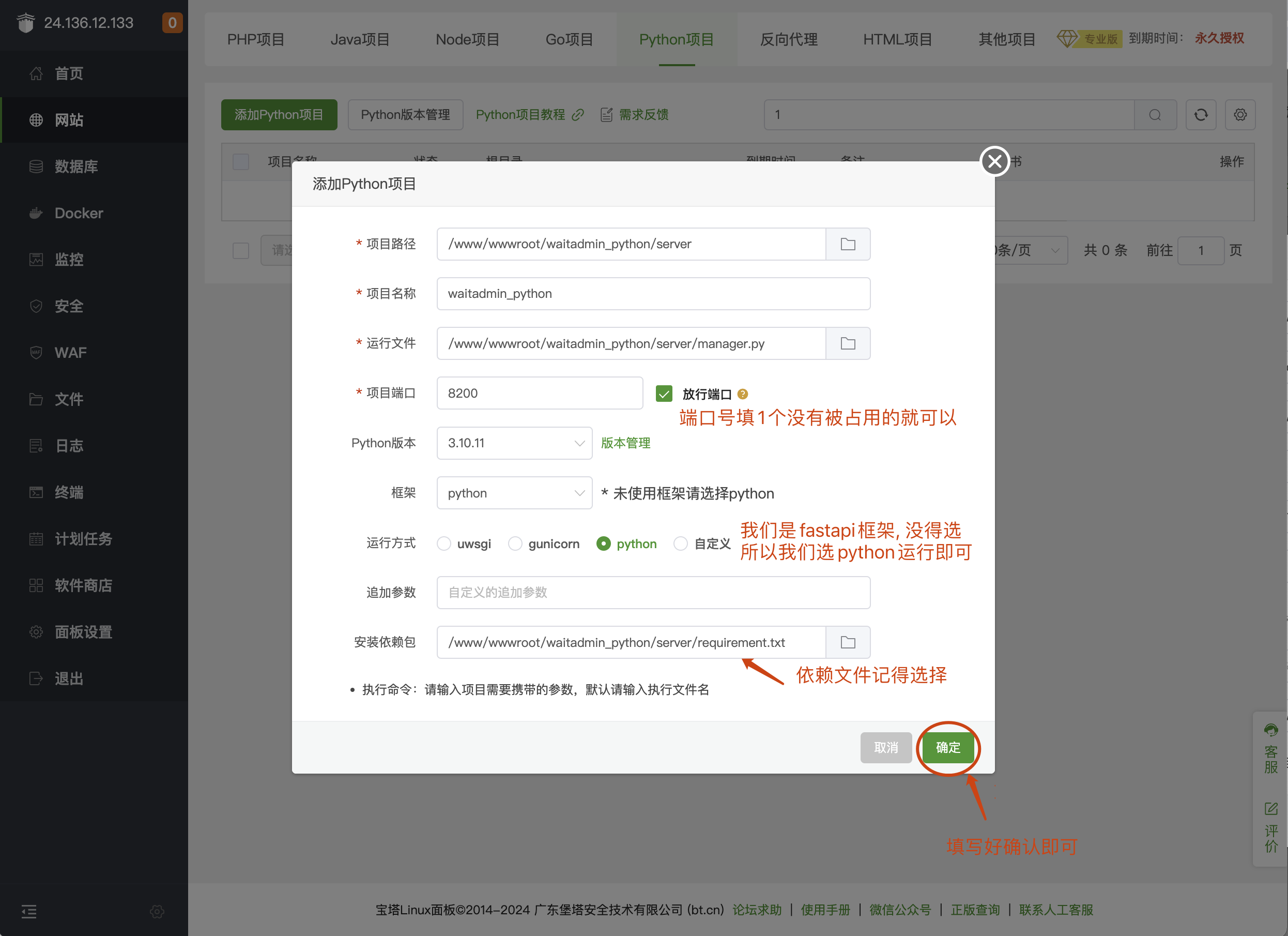
第6步: 设置域名
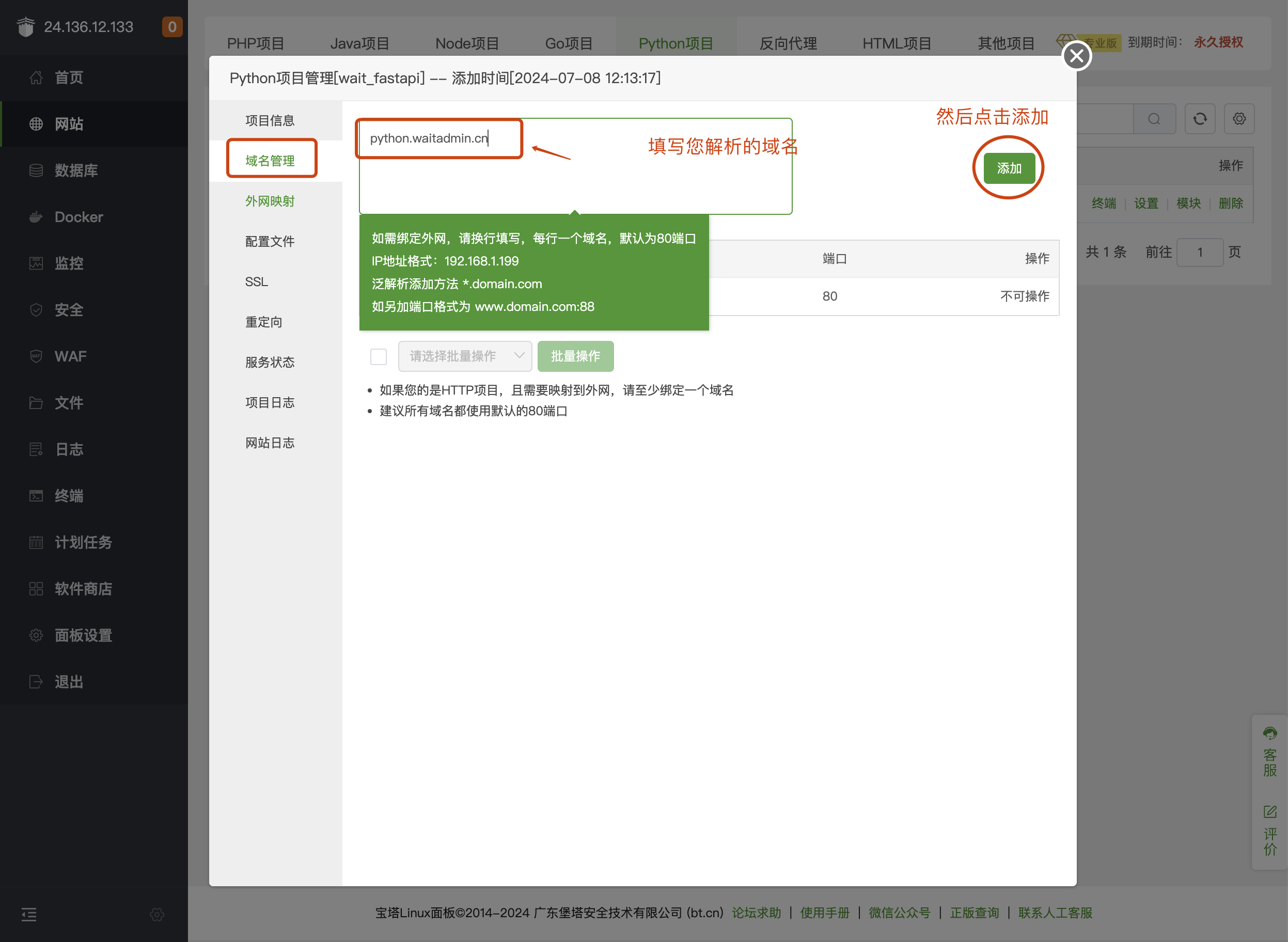
第7步: 设置外网映射
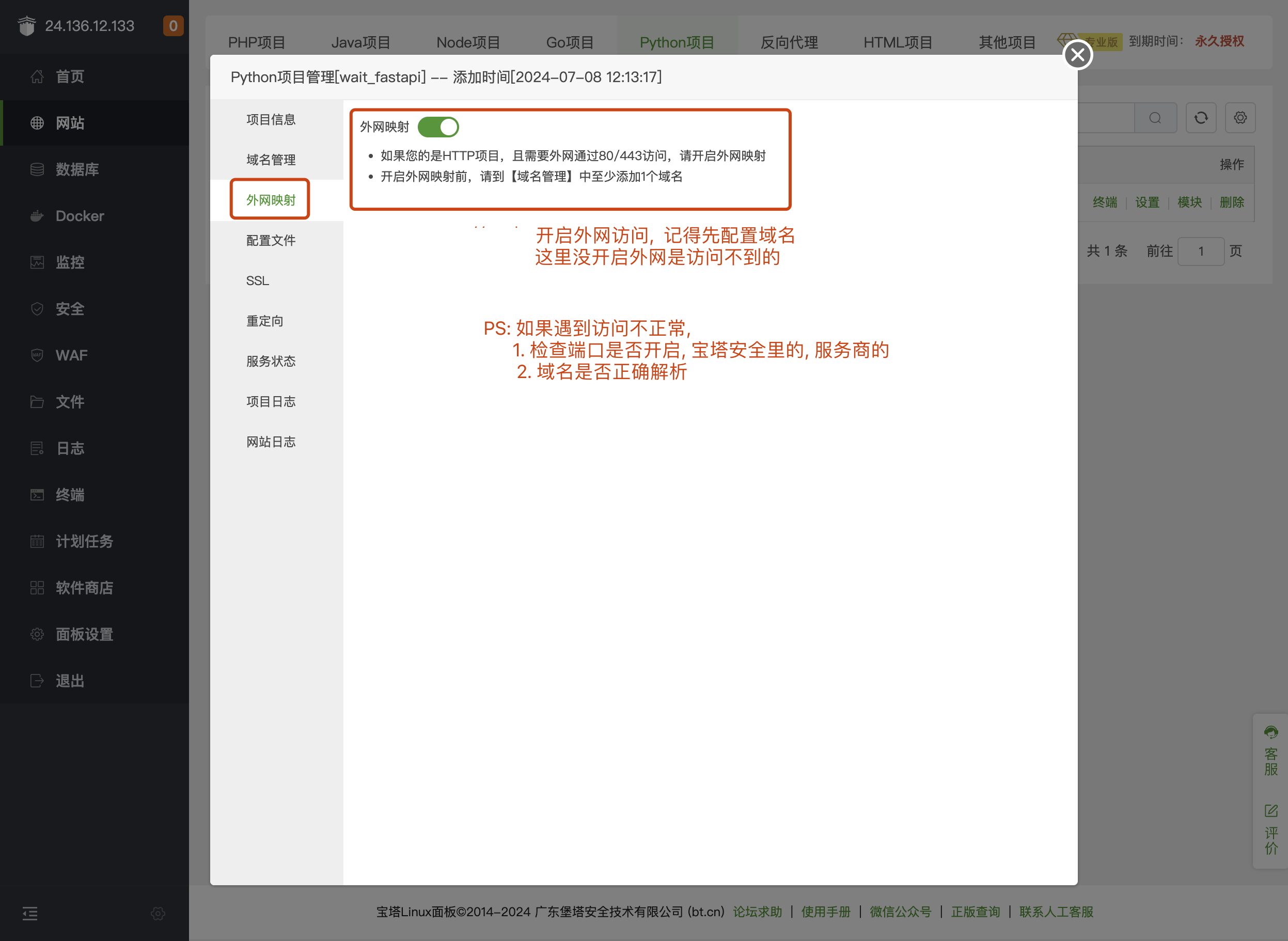
第8步: 设置反向代理
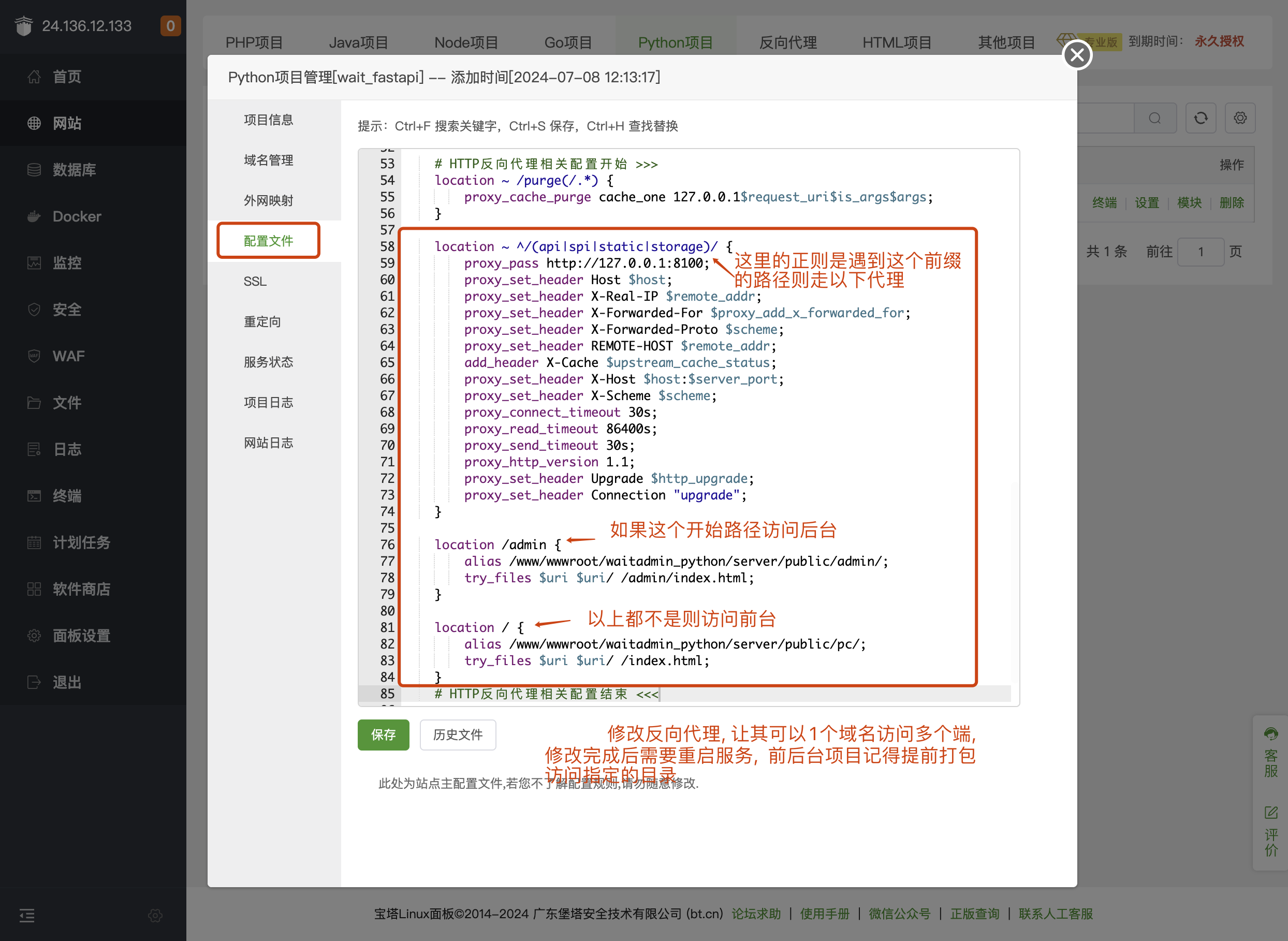
Nginx反向代理
注意
- Nginx的反向代理配置, 以下配置可以让你一个域名多个端访问。
- 当然如果需要单独部署每个服务也是可以的, 如果你知道怎么做的话。
这里有必要了解一下, 我们的源码默认情况下是有3个端的源码。
- server: (服务端) 提供前后台接口
- admin: (后台端) Vue做的后台, 给管理员用的
- nuxtJs: (前台端) Vue做的前台, 展示给用户的
# HTTP反向代理相关配置开始 >>>
location ~ /purge(/.*) {
proxy_cache_purge cache_one 127.0.0.1$request_uri$is_args$args;
}
location ~ ^/(api|spi|static|storage)/ {
proxy_pass http://127.0.0.1:8100;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_set_header REMOTE-HOST $remote_addr;
add_header X-Cache $upstream_cache_status;
proxy_set_header X-Host $host:$server_port;
proxy_set_header X-Scheme $scheme;
proxy_connect_timeout 30s;
proxy_read_timeout 86400s;
proxy_send_timeout 30s;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
}
location /admin {
alias /www/wwwroot/waitadmin_python/server/public/admin/;
try_files $uri $uri/ /admin/index.html;
}
location / {
alias /www/wwwroot/waitadmin_python/server/public/pc/;
try_files $uri $uri/ /index.html;
}
# HTTP反向代理相关配置结束 <<<
第8步: 完成部署
路由
为了减少工作量, 本程序实现了自动注册路由的功能, 但前提是按照约定的规则进行书写代码才可以。
具体可以阅读代码,按照原有的代码风格进行书写即可。
# 约定的规则1: 这里接收的变量名只能是 router 不是是其它的
router = APIRouter(prefix="路由前缀", tags=["描述标签"])
# 约定的规则2: prefix前缀会自动拼接到路径上, 建议根据文件来命名前缀
配置路由
路由的配置放在了根目录下的 config.py 文件
| 名称 | 默认 | 快捷方法 |
|---|---|---|
| ROUTER_ALIAS | {"admin": "spi", "api": "api"} | 给模块指定别名 |
| ROUTER_REMARK | {"admin": "后台接口", "api": "前台接口"} | 给模块指定描述,用于接口文档 |
| ROUTER_STYLES | line | 路由风格,可选值: line, dot |
| ROUTER_PREFIX | True | 是否自动补全目录前缀 |
注册路由
要使用Route类注册路由必须首先在路由定义文件开头创建实例
# 最基础的路由定义方法
router = APIRouter(prefix="路由前缀", tags=["描述标签"])
例如注册如下路由规则:
# 创建路由
router = APIRouter(prefix="/login", tags=["登录系统"])
# 使用路由
@router.post("/check", summary="登录验证")
async def check(request: Request, params: schema.LoginCheckIn):
pass
最终我们访问的路径是:
https://serverName/api/login/check
# 路径说明:
# https://serverName (域名)
# api (模块名)
# login (前缀名)
# check (方法名)
路由参数
FastAPI 允许开发者通过简洁的Python语法声明路径参数,实现动态路由及参数处理。
基础概念
- 路径参数: 路径中包含的动态部分,用花括号 {} 包裹,如 /items/{item_id} 中的 item_id。
- 示例: 路径 /items/123 将传递参数 item_id 值为 123。
声明路径参数
# 方法示例
@router.get("/items/{item_id}")
async def read_item(item_id):
# item_id 为路径的参数
return {"item_id": item_id}
# 访问: http://127.0.0.1:8000/items/foo
# 响应: {"item_id": "foo"}。
数据类型转换 使用标准的 Python 类型标注为函数中的路径参数声明类型,并且自动转换标注的数据类型。
# 声明
@路由.请求方式("路径/{参数}")
async def 函数名(参数名:类型):
return 返回数据
#示例
@router.get("/items/{item_id}")
async def read_item(item_id: int):
return {"item_id": item_id}
# 访问: http://127.0.0.1:8000/items/3
# 响应: {"item_id": 3},自动将字符串 “3” 转换为整型。
# 访问: http://127.0.0.1:8000/items/foo
# 响应: 则返回错误信息,因为 “foo” 不能转换为整数。
参数类型
基本类型:
int: 整数类型,如item_id: int,会自动将路径中的字符串转换为整数。float: 浮点数类型,同理,会转换字符串到浮点数。str: 字符串类型,这是默认类型,通常不需要显式声明,但可以用于明确意图。bool: 布尔类型,虽然不常用作路径参数,但在某些场景下可能有其用途。
复合类型
List[类型]或Sequence[类型]: 允许参数为一个列表或序列,如tags: List[str]表示多个标签。Dict[str, 类型]或Mapping[str, 类型]: 接受字典作为参数,键通常是字符串。Union[类型1, 类型2, ...]: 表示参数可以是多个类型中的任意一种。
自定义类型
Pydantic模型: 可以定义Pydantic模型作为路径参数类型,用于复杂的数据结构验证, 如user: UserInPath,其中UserInPath是一个Pydantic模型。Enum类型: 如上文所述,使用枚举(Enum)来限制路径参数的取值范围,提供额外的验证和清晰性。
特殊类型转换器
- 路径转换器(如 path)可以用于处理路径中包含斜杠的特殊参数,例如 file_path: Path 使用 path 转换器。
可选参数与默认值
- 使用默认值(如 item_id: int = None)可以标记路径参数为可选,尽管这在路径参数中较少见,因为路径通常要求所有组件都是必需的。
请求方法
| 类型 | 描述 | 快捷方法 |
|---|---|---|
| GET | GET请求 | get |
| POST | POST请求 | post |
| PUT | PUT请求 | put |
| DELETE | DELETE请求 | delete |
| PATCH | PATCH请求 | patch |
| HEAD | HEAD请求 | head |
| OPTIONS | OPTIONS请求 | options |
| * | 指定请求 | api_route |
使用示例如下:
@router.get('/new') // 定义GET请求路由规则
@router.post('/new') // 定义POST请求路由规则
@router.put('/new'); // 定义PUT请求路由规则
@router.delete('/new'); // 定义DELETE请求路由规则
@router.api_route('/new', methods=["GET", "POST"]); // 定义请求指定的路由规则
模型
简介
Tortoise ORM 是一个为异步Python应用设计的ORM(对象关系映射)库;
Tortoise ORM 支持多种数据库后端,如PostgreSQL、MySQL和SQLite等;
它允许开发者以面向对象的方式与关系型数据库进行交互, 同时充分利用异步编程提高性能;
核心概念:
- 模型(Models): 使用Python类来定义数据库表结构。每个类代表1个数据库表,类的属性对应表中的列。
- 字段(Fields): 在模型中定义字段, 这些字段映射到数据库表的列。
- 关系(Relations): 支持定义模型之间的关系, 如一对一、一对多、多对多等。
应用场景:
- 构建高性能的异步Web应用,如使用FastAPI、Sanic或Starlette的应用;
- 需要面向对象方式操作数据库的项目。
- 需要异步数据库访问以提高应用性能的场景。
核心功能
- 模型定义: 通过Python类定义数据库表结构。
- 数据查询: 支持复杂的查询构建和执行。
- 数据操作: 支持创建、更新、删除数据库记录。
- 关系管理: 支持定义和查询模型之间的关系。
- 迁移和同步: 提供数据库迁移工具,用于管理数据库模式的变更。
配置文件
配置文件在项目根目录的 config.py
DATABASES: Dict[str, object] = {
'connections': {
'mysql': {
'engine': 'tortoise.backends.mysql',
'prefix': os.getenv('DB:MYSQL_PREFIX', ''),
'credentials': {
# 服务器地
'host': os.getenv('DB:MYSQL_HOST', '127.0.0.1'),
# 服务器端口
'port': int(os.getenv('DB:MYSQL_PORT', 3306)),
# 数据库用户
'user': os.getenv('DB:MYSQL_USERNAME', 'root'),
# 数据库密码
'password': os.getenv('DB:MYSQL_PASSWORD', 'root'),
# 数据库名称
'database': os.getenv('DB:MYSQL_DATABASE', ''),
# 最少连接数
'minsize': int(os.getenv('DB:MYSQL_MINSIZE', 1)),
# 最大连接数
'maxsize': int(os.getenv('DB:MYSQL_MAXSIZE', 100)),
# 数据库编码
'charset': os.getenv('DB:MYSQL_CHARSET', 'utf8mb4'),
# 打印SQL
'echo': True if os.getenv('DB:MYSQL_ECHO', 'False') == 'True' else False
}
},
'pgsql': {
'engine': 'tortoise.backends.asyncpg',
'credentials': {
# 服务器地址
'host': os.getenv('DB:PGSQL_HOST', '127.0.0.1'),
# 服务器端口
'port': int(os.getenv('DB:PGSQL_PORT', 5432)),
# 数据库用户
'user': os.getenv('DB:PGSQL_USERNAME', 'postgres'),
# 数据库密码
'password': os.getenv('DB:PGSQL_PASSWORD', '123456'),
# 数据库名称
'database': os.getenv('DB:PGSQL_DATABASE', 'postgres'),
# 最少连接数
'minsize': int(os.getenv('DB:PGSQL_MINSIZE', 1)),
# 最大连接数
'maxsize': int(os.getenv('DB:PGSQL_MAXSIZE', 100)),
# 打印SQL
'echo': os.getenv('DB:MYSQL_ECHO', False)
}
}
},
'apps': {
# 配置MySQL
'mysql': {'models': 'common.models', 'default_connection': 'mysql'},
# 配置PgSQL
'pgsql': {'models': 'common.postgres', 'default_connection': 'pgsql'},
},
# 是否使用时区支持
'use_tz': False,
# 默认使用的时区
'timezone': 'Asia/Shanghai'
}
字段类型
CharField (字符串)
| 名称 | 类型 | 默认 | 描述 |
|---|---|---|---|
| pk | bool | False | 是否将此字段设置为主键 |
| null | bool | False | 是否允许字段为NULL |
| default | Any | - | 字段的默认值 |
| unique | bool | False | 字段值是否必须在数据库中唯一 |
| index | bool | False | 是否为该字段创建索引 |
| max_length | int | - | 字符串的最大长度 |
| description | str | - | 字段的描述信息(主要用于文档和生成的SQL schema) |
| generated | bool | False | 是否为自动生成的字段(如自增主键) |
FloatField (浮点型)
| 名称 | 类型 | 默认 | 描述 |
|---|---|---|---|
| default, null, unique, index, description, pk, generated | - | - | 与CharField相同 |
| gt, lt, ge, le | float | - | 字段值的范围限制 |
IntegerField (整数型)
| 名称 | 类型 | 默认 | 描述 |
|---|---|---|---|
| default, null, unique, index, description, pk, generated | - | - | 与CharField相同 |
| gt, lt, ge, le | int | - | 字段值的范围限制 |
BooleanField (布尔型)
| 名称 | 类型 | 默认 | 描述 |
|---|---|---|---|
| default, null, description | - | - | 与CharField相同 |
DateField 和 DateTimeField (日期时间型)
| 名称 | 类型 | 默认 | 描述 |
|---|---|---|---|
| default, null, unique, index, description, pk | - | - | 与CharField相同 |
| auto_now | bool | False | 如果设置为True,则在对象保存时自动设置为当前日期/时间 |
| auto_now_add | bool | False | 如果设置为True,则在对象第一次保存时自动设置为当前日期/时间 |
ForeignKeyField (关系型)
| 名称 | 类型 | 默认 | 描述 |
|---|---|---|---|
| default, null, description, pk, index | - | - | 与CharField相同 |
| to | str or Type[Model] | - | 指定外键关联的模型 |
| related_name | str | - | 在关联模型上创建反向关系的名称 |
| on_delete | str | - | 当关联的对象被删除时的行为(如CASCADE、SET_NULL等) |
ManyToManyField (关系型)
| 名称 | 类型 | 默认 | 描述 |
|---|---|---|---|
| default, null, description, pk, index | - | - | 与CharField相同 |
| through | str or Type[Model] | - | 用于定义多对多关系的中间表。如果不指定,Tortoise ORM将自动创建一个中间表 |
| related_name | str | - | 与ForeignKeyField中的用法相同,用于反向查询 |
TextField (文本型)
| 名称 | 类型 | 默认 | 描述 |
|---|---|---|---|
| default, null, description | - | - | 与CharField相同。通常用于存储大量文本 |
JSONField (序列化型)
| 名称 | 类型 | 默认 | 描述 |
|---|---|---|---|
| default, null, description | - | - | 与CharField相同。用于存储JSON格式的数据 |
添加数据
student = await Student.create(
nickname='小明',
username='wait'
)
print(student.id)
更新数据
# 根据id修改学生数据
update_num = await Student.filter(id=1).update(name="赵不柱")
# 批量更新
students = await Student.all()
for student in students:
student.name += "@"
student.save()
删除数据
delete_num = await Student.filter(id=1).delete()
查询数据
all查询多个结果: (不存在返回[])get查询单一对象: (不存在抛出DoesNotExist)first查询单一对象: (不存在返回None)count查询多个结果: (不存在返回0)
获取单个数据
注意
模型使用 get 方法查询, 如果数据时抛出异常 DoesNotExist, 否则返回当前模型的对象实例。 另外还提供了 get_or_none 查询方法, 数据不存在是返回 None 不会抛出异常。
# 1、取出主键为1的数据
student = await Student.get(id=1)
print(student)
# 2、使用查询构造器查询满足条件的数据
student = await Student.filter(name="waitadmin").get(id=1)
print(student.name)
# 3、查询1条数据不存在时返回None, 否则返回数据对象
student = await Student.filter(id=1).get_or_none()
if student:
print(student.name)
else:
print("student not found")
注意
模型使用 first 方法查询, 如果数据不存在返回None, 否则返回当前模型的对象实例。
如果希望查询数据不存在则返回一个空模型, 可以使用以下的方法。
student = await Student.filter(id=1).first()
获取多个数据
注意
all() 方法用于查询所有数据, 返回所有数据集 (QuerySet对象)。
如果不添加任何条件, 它会返回表中的所有记录。
- 取出多个数据:
# 根据状态获取多个数据
lists = await Student.filter(status=1).all()
# 对数据集进行遍历操作
for lists in student:
print(student.name)
- 更多查询支持:
# 使用查询构造器查询
lists = await Student.filter(status=1).limit(3).order_by("-sort", "id").all()
for lists in student:
print(student.name)
用查询构造器
在模型中仍然可以调用数据库的链式操作和查询方法, 可以充分利用数据库的查询构造器的优势。
await Student.filter(id=1).first()
await Student.filter(status=1).order_by("-sort", "id").all()
await Student.filter(status=1)->limit(10).all()
只查指定字段
在模型中可以使用 values 指定查询那些字段, 这样可以过滤不需要的字段提高查询的效率。
# 只查询自定的字段
await Student.filter(id=1).first().values(["id", "name"])
# 最终生成的SQL:
SELECT id, name FROM student;
查询表达式
| 表达式 | 符号 | 含义 |
|---|---|---|
| = | = | 等于 |
| not | <> | 不等于 |
| gt | > | 大于 |
| gte | >= | 大于等于 |
| lt | < | 小于 |
| lte | <= | 小于等于 |
| contains | %like% | 模糊查询(前后匹配, 不区分大小写) |
| icontains | %ilike% | 模糊查询(前后匹配, 区分大小写) |
| startswith | like% | 模糊查询(尾部匹配, 不区分大小写) |
| istartswith | ilike% | 模糊查询(尾部匹配, 区分大小写) |
| endswith | %like | 模糊查询(头部匹配, 不区分大小写) |
| iendswith | %ilike | 模糊查询(头部匹配, 区分大小写) |
| isnull | isnull | 是否为null |
| not_isnull | not_isnull | 是否不为null |
| iexact | iexact | nginx |
| search | search | nginx |
| year | year | nginx |
| month | month | nginx |
| day | day | nginx |
- 表达式示例:
表达: __contains
条件: %like% (不区分大小写)
查询: ArticleModel.filter(title__contains='Python').values('id', 'title').sql()
返回: SELECT `id` `id`,`title` `title` FROM `wait_article` WHERE CAST(`title` AS CHAR) LIKE '%Python%'
# ------------------------------------------
表达: __icontains
条件: %like% (区分大小写)
查询: ArticleModel.filter(title__icontains='Python').values('id').sql()
返回: SELECT `id` `id`,`title` `title` FROM `wait_article` WHERE UPPER(CAST(`title` AS CHAR)) LIKE UPPER('%Python%')
# ------------------------------------------
表达: __startswith
条件: like%
查询: ArticleModel.filter(title__startswith='Python').values('id', 'title').sql()
返回: SELECT `id` `id`,`title` `title` FROM `wait_article` WHERE CAST(`title` AS CHAR) LIKE 'Python%'
# ------------------------------------------
表达: __istartswith
条件: ilike%
查询: ArticleModel.filter(title__istartswith='Python').values('id', 'title').sql()
返回: SELECT `id` `id`,`title` `title` FROM `wait_article` WHERE UPPER(CAST(`title` AS CHAR)) LIKE UPPER('Python%')
# ------------------------------------------
表达: __endswith
条件: %like
查询: ArticleModel.filter(title__endswith='Python').values('id', 'title').sql()
返回: SELECT `id` `id`,`title` `title` FROM `wait_article` WHERE CAST(`title` AS CHAR) LIKE '%Python'
# ------------------------------------------
表达: __iendswith
条件: %ilike
查询: ArticleModel.filter(title__iendswith='Python').values('id', 'title').sql()
返回: SELECT `id` `id`,`title` `title` FROM `wait_article` WHERE UPPER(CAST(`title` AS CHAR)) LIKE UPPER('%Python')
# ------------------------------------------
表达: __isnull
条件: isnull
查询: ArticleModel.filter(title__isnull='').values('id', 'title').sql()
返回: SELECT `id` `id`,`title` `title` FROM `wait_article` WHERE NOT `title` IS NULL
# ------------------------------------------
表达: __not_isnull
条件: not_isnull
查询: ArticleModel.filter(title__not_isnull='').values('id', 'title').sql()
返回: SELECT `id` `id`,`title` `title` FROM `wait_article` WHERE NOT `title` IS NULL
# ------------------------------------------
表达: __iexact
条件: iexact
查询: ArticleModel.filter(title__iexact='Python').values('id', 'title').sql()
返回: SELECT `id` `id`,`title` `title` FROM `wait_article` WHERE UPPER(CAST(`title` AS CHAR))=UPPER('Python')
用聚合查询
在SQL中, 聚合查询通常涉及 COUNT(), SUM(), AVG(), MAX(), MIN() 等函数。
注意实现:
- 1、聚合查询的结果通常是异步的, 因此你需要使用 await 关键字来获取结果。
- 2、当你使用
annotate()方法时, 你需为聚合函数提供1个字段名作为参数(例如: Count('id'))。 - 3、你可以使用
values()或values_list()方法来选择要在结果集中返回的字段。 - 4、
values()返回一个字典列表,而 values_list() 返回一个元组列表。 - 5、
having()方法用于在聚合查询的结果上应用过滤条件。它接受一个或多个表达式作为参数。
假设你有一个
User模型:
from tortoise.models import Model
from tortoise import fields
class User(Model):
id = fields.IntField(pk=True)
name = fields.CharField(max_length=100)
age = fields.IntField()
- 计算表中的记录数:
from tortoise.functions import Count
from .models import User
async def count_users():
count = await User.all()\
.annotate(Count('id'))\
.values_list('id__count', flat=True)\
.first()
return count
- 复杂的聚合查询:
from tortoise.functions import Count
from .models import User
async def count_users_by_age():
# 按年龄分组并计算每个年龄组的用户数
query = await User.all()\
.annotate(Count('id'))\
.values('age', 'id__count')\
.order_by('age')
return query
# 在这个例子中, 我们使用了 annotate() 方法来添加聚合函数,
# 并使用 values() 方法来选择要在结果集中返回的字段。
- 计算某个字段的平均值:
from tortoise.functions import Avg
from .models import User
async def avg_user_age():
avg_age = await User.all()\
.annotate(Avg('age'))\
.values_list('age__avg', flat=True)\
.first()
return avg_age
- 使用
HAVING子句进行过滤:
from tortoise.functions import Count
from .models import User
async def count_users_by_age_with_filter():
query = await User.all()\
.annotate(Count('id'))\
.values('age', 'id__count')\
.having(Count('id') > 10)\
.order_by('age')
return query
F对象
之前的查询都是对象的属性与常量值比较,两个属性怎么比较呢?答:使用F对象。
语法如下:
filter(字段名__运算符=F('字段名'))
使用示例:
from tortoise.query_utils import F
from .models import BookInfo
# --------------- 示例1 ---------------
# 查询阅读量大于等于评论量的图书
results = await BookInfo.filter(readcount__gt=F('commentcount'))
# 输出的结果:
<QuerySet [<BookInfo: 雪山飞狐>]>
# --------------- 示例2 ---------------
# 可以在F对象上使用算数运算
# 查询阅读量大于2倍评论量的图书
results = await BookInfo.filter(readcount__gt=F('commentcount')*2)
# 输出的结果:
<QuerySet [<BookInfo: 雪山飞狐>]>
Q对象
Tortoise-ORM 的 Q 对象允许你通过逻辑和比较操作符构建复杂的查询条件。
通过使用 Q 对象,开发者可以组合多个查询条件,包括逻辑操作符(如 AND、OR、NOT)
和比较操作符(如 =、>、< 等),从而构建出复杂的查询逻辑,满足各种数据检索需求。
语法如下:
Q(属性名__运算符=值)
使用示例1:
- 如果需要实现逻辑或
or的查, 需要使用Q()对象结合|运算符
from tortoise.query_utils import Q
from .models import BookInfo
# 查询阅读量大于20的图书,改写为Q对象如下
results = await BookInfo.filter(Q(readcount__gt=20)|Q(id__lt=3)).all()
# 输出的结果:
<QuerySet [<BookInfo: 射雕英雄传>, <BookInfo: 天龙八部>, <BookInfo: 雪山飞狐>]>
使用示例2:
Q对象可以使用&、|连接,&表示逻辑与,|表示逻辑或
from tortoise.query_utils import Q
from .models import BookInfo
# 查询阅读量大于20,或编号小于3的图书,只能使用Q对象实现
results = await BookInfo.filter(Q(readcount__gt=20)|Q(id__lt=3)).all()
# 输出的结果:
<QuerySet [<BookInfo: 射雕英雄传>, <BookInfo: 天龙八部>, <BookInfo: 雪山飞狐>]>
使用示例3:
Q对象前可以使用~操作符,表示非not。
from tortoise.query_utils import Q
from .models import BookInfo
# 查询编号不等于3的图书
# 方式1:
results = await BookInfo.exclude(id=3).all()
# 方式2:
results = await BookInfo.filter(~Q(id=3)).all()
工具
邮件发送
- 邮件发送驱动库:
pip3 install aiosmtplib - 该库的文档地址:
https://aiosmtplib.readthedocs.io/en/stable/usage.html
邮件驱动类: from plugins.mail.driver import MailDriver
| 方法名 | 必填 | 说明 |
|---|---|---|
| subject(title: str) | 是 | 邮件标题 |
| body(body: str) | 否 | 邮件内容 |
| add_alternative(body: str, subtype: str = "html") | 否 | HTML内容 |
| add_attachment(path: str, filename: str, maintype: str, subtype: str) | 否 | 邮件附件 |
| fromm(address: str) | 否 | 发送者邮箱 |
| to(address: Union[str, List[str]]) | 否 | 接受者邮箱 |
| cc(address: Union[str, List[str]]) | 否 | 抄送者邮箱 |
| smtp | 否 | 邮箱的实例 |
发送场景1:
# 导入邮件发送驱动
from plugins.mail.driver import MailDriver
# 最基础的邮件发送
await MailDriver()
.subject("邮件的标题")
.body("邮件的内容")
.to("fs@qq.com")
.send()
# 说明:
# 1、以上方式是最基础的发送方式,需要在后台配置好邮件参数才可以发送。
# 2、看着没让你传递授权密码这些参数,其实这个类里面封装好了读取参数。
# 3、send 方法一定要在最后调用,表示链条已经构建好可以发送了。
# 其它:
# 1、如果你不想用后台配置的邮件参数,有需求需要另外的邮件参数作为发送。
# 2、您可以在类的初始化传递邮件配置的相关参数,具体参数如下:
await MailDriver(
host="smtp.163.com",
port=25,
username="...",
password="...",
ssl=False
).subject("邮件的标题")
.body("邮件的内容")
.send()
发送场景2:
from plugins.mail.driver import MailDriver
# 发送带附件的邮件
path: str = "/www/aa.png"
await MailDriver()
.subject("邮件的标题")
.body("邮件的内容")
.add_attachment(path, "aa.png", "image", "png")
.to("fs@qq.com")
.send()
发送场景3:
from plugins.mail.driver import MailDriver
# 发送HTML格式内容
content: str = "<p>内容</p>"
await MailDriver()
.subject("邮件的标题")
.body("邮件的内容")
.add_alternative(content, "html")
.to("fs@qq.com")
.send()
发送场景4:
from plugins.mail.driver import MailDriver
from email.mime.text import MIMEText
# 组装发送的数据内容
mime_message = MIMEText("Sent via aiosmtplib")
mime_message["From"] = "root@localhost"
mime_message["To"] = "somebody@example.com"
mime_message["Subject"] = "Hello World!"
# 获取邮件的发送对象
smtp_client = await MailDriver().smtp()
await smtp_client.send_message(message)
await smtp_client.quit()
短信发送
短信驱动类: from plugins.mail.driver import SmsDriver
| 方法名 | 必填 | 说明 |
|---|---|---|
| mobile | 是 | 手机号码 |
| template_id | 是 | 模板ID |
| template_params | 否 | 模板参数 |
发送场景1:
# 导入短信发送驱动
from plugin.mail.driver import SmsDriver
result = await SmsDriver().send_sms(
mobile=13800138000,
template_id="98877545",
template_params={"code": "4533"}
)
消息通知
- 消息通知是根据场景编码发送
短信通知、邮件通知、系统通知 - 具体发送配置在
后台-设置-通知设置 - 增加更多通知场景,你应该了解下数据表
wait_notice_setting
# 发送邮件验证码 给指定邮箱 (scene=106)
await MsgDriver.send(scene, {
"email": "waitadmin@163.com",
"code": 3456
})
# 发送短信验证码 给指定手机 (scene=101)
await MsgDriver.send(scene, {
"mobile": "13800138000",
"code": 3456
})